-
Exponential Moving Average (EMA) in ML카테고리 없음 2022. 2. 21. 16:24
Swin Transfer의 이점을 복사한 ConvNet에 대한 논문을 읽다가 새로운 optimization 기법인 EMA를 처음 접하게 되었다. EMA가 도대체 무엇이길래 기존 basline보다 성능이 더 향상되었는지(단순히 optimization을 EMA로 사용했다는 이유만으로) 궁금하여 공부해보았고, 따라서 이번 포스트에서는 딥러닝적 관점에서 EMA에 대해 설명하도록 하겠다.
Exponential Moving Average(EMA)
EMA 알고리즘은 시계열 데이터에 대해 많이 사용되는데, 그 이유는 EMA가 효율적으로 시계열 데이터의 noise를 줄여주기 떄문이다. (data를 smoothing하는 효과를 가져온다!) EMA를 구현하는 방법은 단순히 최근 정보에는 높은 가중치를 주고 오래된 과거는 낮은 가중치를 주어 평균을 구하면 된다. Andrew Ng 씨의 강의 ppt 자료를 통해 더 자세히 설명하도록 하겠다.
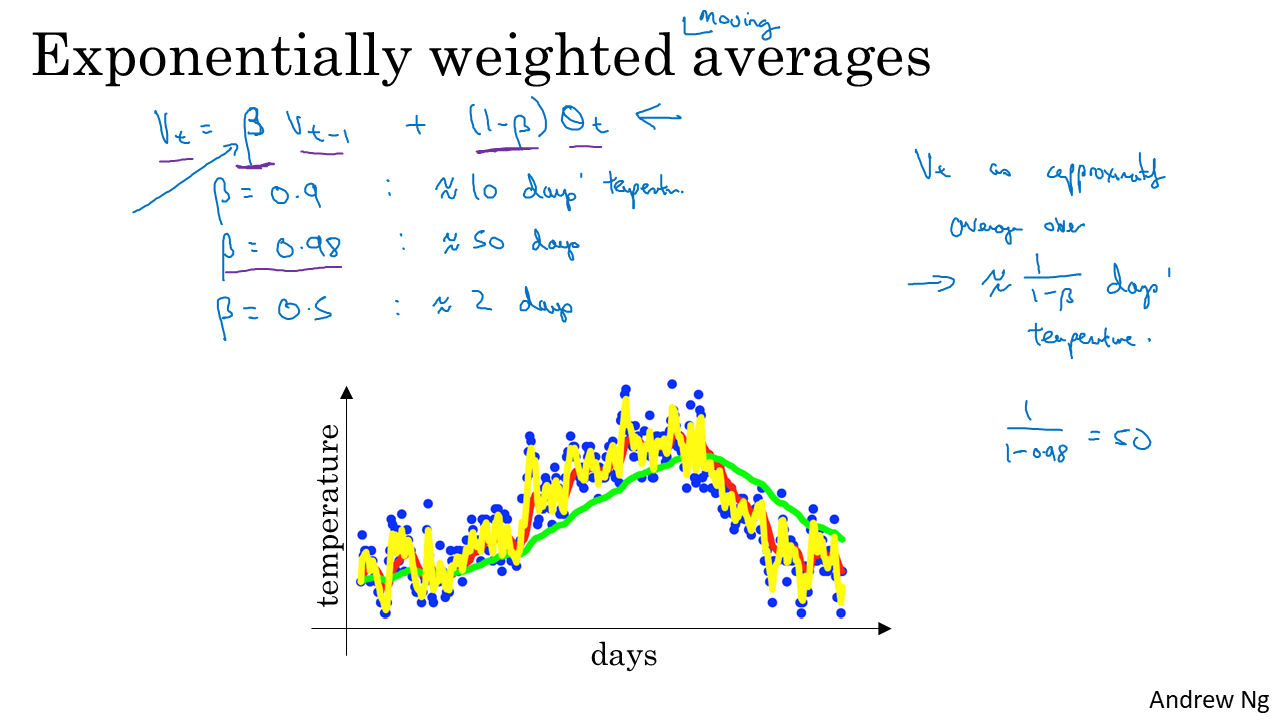
위 그림은 시간에 따른 온도의 변화량을 나타낸 그래프로, 이동평균 (moving average)를 계산하는 예제이다. 상수 β에 대해 vt=β∗vt−1+(1−β)∗θt 라고 할 수 있는데 이를 전개해보면 vt는 지수적으로 감소하는 가중치를 지닌 θ값들의 합으로 표현 가능하다. β가 1에 가까워지면 더 오랜 시간 동안의 평균값을 참고하는 것이기 때문에 β가 1에 수렴할수록 곡선이 더 완만해진다(smoothing 효과가 커진다). 다시말해 β가 커질수록 θ가 바뀔때 EMA가 더 느리게 반응하므로 latency가 커진다.
그렇다면 EMA를 딥러닝에 어떻게 적용할 수 있을까?
gradient descent 방법에 EMA를 적용한 것이 바로 momemtum이 되겠다.
Momemtum
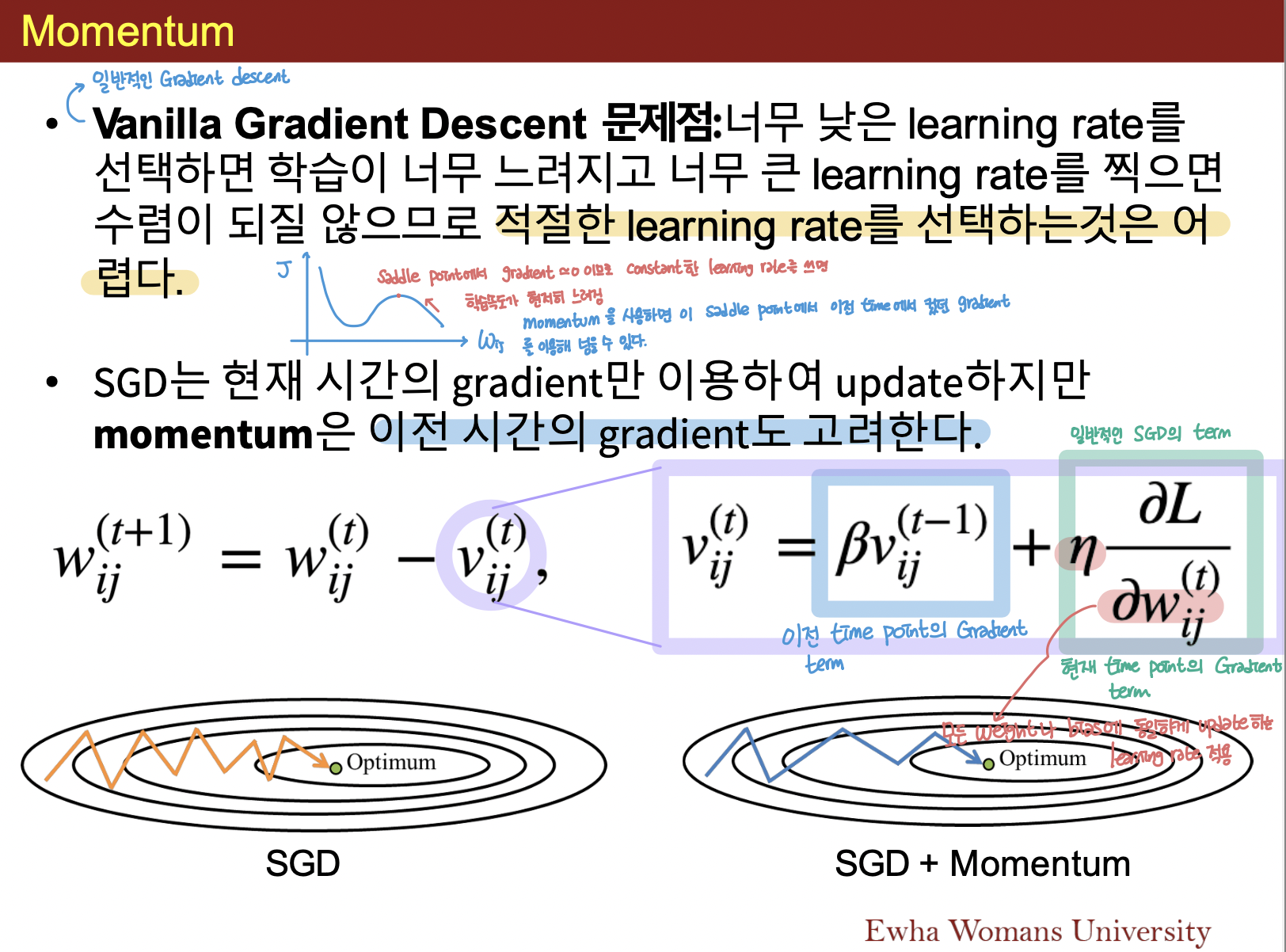
위 자료처럼 momentum은 현재 시간의 gradient 뿐만 아니라 이전시간의 gradient도 고려하여 gradient를 update해준다. momentum을 이용하면 saddle point에서 이전 time에서의 gradient 정보를 이용해 넘을 수 있다고 한다.
Momentum은 모든 weight bias term에 동일하게 update하는 learning rate를 적용하고 있는데 모든 weight bias term들이 동일한 속도로 최적화 지점에 도달하지는 않을 것이다. 따라서 이미 충분히 학습한 weight에 대해서는 learning rate를 slow down시켜주고, 아직 학습이 필요한 weight는 속도를 높여줬을 때 더 효과적으로 학습이 될 것이라 학자들은 예측하였고 이런 배경에서 Adagrad가 제시되었다.
우리가 흔히 쓰는 optimizer인 Adam은 Momentum과 RMSProp를 합친 방법이다. momentum을 조절하는 v와 learning rate를 조절하는 g 둘다 지수평균으로 나타내기 때문에 Adam에는 EMA의 concept이 사용되었다고 봐도 무방하다.
여기까지는 무리없이 이해할 수 있었다. 하지만 내가 이해가 안된 부분은 최근, pytorch 환경에서 EMA를 implementation하는 방법이다. 많은 엔지니어들은 optimizer를 적용한 이후에 다시 weight에 대해 EMA를 apply해준다.
We use Exponential Moving Average(EMA) as we find it alleviates larger model's overfitting.
이미 Adam 안에 EMA가 있는데도 불구하고 왜 이동평균을 2번해주는 것일까? 그 이유에 대해서는 다시 공부를 해봐야할 것 같다.