-
Multi GPU 사용하기 및 GPU hang 문제 해결리눅스(Ubuntu) 2022. 4. 6. 18:51
GPU 한개만을 이용해서 deep learning code를 돌릴 수 있지만, 보다 더 나은 성능을 위해 multi GPU를 사용해야하는 상황이 올 수 있다. 사실 multi GPU를 사용하도록 하는 코드는 간단한데 이는 아래와 같다.
1. .py 코드로 돌리는 경우
(1) .py 상에서 모델을 지정해줄 때, 다음과 같이 nn.DataParallel을 사용하여 모델을 랩핑해준다. PyTorch는 기본적으로 하나의 GPU만 사용하기 때문에 DataParallel 을 이용하여 모델을 병렬로 실행해 다수의 GPU 에서 작업을 수행한다.
model = torch.nn.DataParallel(net).cuda()(2) Terminal에서 .py 코드를 돌릴때 명령어 앞에 CUDA_VISIBLE_DEVICES를 설정해준다. 아래 명령어는 GPU #0과 #1을 이용해 my_code.py를 실행하라는 의미이다.
CUDA_VISIBLE_DEVICES=0,1 python my_code.py2. .ipynb 파일로 돌리는 경우
(1) 주피터 노트북을 사용하여 파이썬 스크립트 내에서 코드를 돌리는 경우, 내 코드들의 맨 위에 아래와 같이 작성해주면 된다. 이때 내가 병렬로 처리할 GPU 기기 넘버를 아래와같이 ,를 사용해 할당해주면 된다.
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"]='0,1'(2) .py와 마찬가지로 model을 지정해줄 때 nn.DataParallel으로 랩핑해준다.
model = torch.nn.DataParallel(net).cuda()이렇게하면 대부분의 컴퓨터에서는 무리없이 multi GPU를 쓸 수 있을 것이다. 하지만 간혹, 아래 그림과 같이 GPU-util이 100에서 멈춰버리며, 어떠한 것도 print되지 않는, GPU hang 문제가 발생할 수도 있다. (나의 경우가 그랬다...)
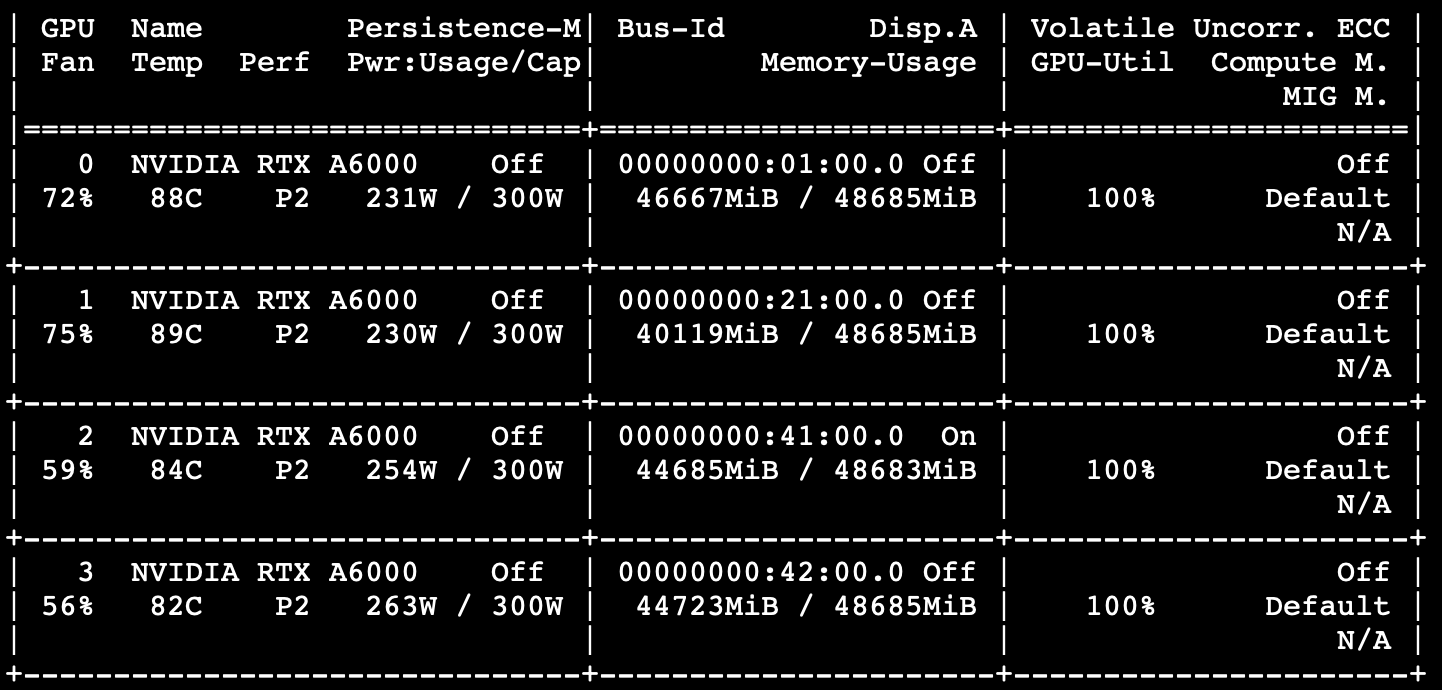
이럴 경우에는 어떻게 해결해야 할까? 수많은 github issue 및 stack overflow 등을 찾아보면서 드디어 내 경우에 맞는 해결방법을 찾았다! 사실 방법은 매우 간단했는데, IOMMU를 disable해주기만 하면 되었다.
1. 먼저 /etc/default/grub 파일에 vi 편집기로 들어간 후
sudo vi /etc/default/grub2. GRUB_CMDLINE_LINUX=""라고 되어있는 부분을 "iommu=soft"로 바꿔준 후 변경사항을 저장해준다.
#GRUB_CMDLINE_LINUX="" <----- Original commented GRUB_CMDLINE_LINUX="iommu=soft" <------ Change3. 그러고 난 뒤 udate를 시켜 준 후,
sudo update-grub4. 재부팅해주면 이상없이 multi GPU code가 잘 돌아가는 것을 확인할 수 있다.
sudo reboot'리눅스(Ubuntu)' 카테고리의 다른 글
사용자계정 추가하기 (0) 2021.12.08 Ubuntu(우분투) 재설치 방법(2) (0) 2021.12.06 Ubuntu(우분투) 재설치 방법(1) (0) 2021.11.29 RTX a6000 pytorch 버전 문제 해결 (0) 2021.10.28 (Ubuntu) Nvidia-driver 가 깨졌을 때 해결 방법 (0) 2021.07.21