-
Markov Decision ProcessDeep Reinforcement Learning 2021. 11. 17. 20:55
랩실 언니의 작업을 이어받아서 하는 이번 프로젝트는 reinforcement learning을 이용한 object localization이다. supervised learning을 주로 접해본 나로는 각 state마다 정답 없이 보상만 주어지는 강화학습의 알고리즘이 신기했다. 기본적인 강화학습 알고리즘 공부를 하다 강화학습과 Markov Deicision Process (MDP)는 매우 밀접한 관계가 있음을 알게 되었다. 따라서 이번 포스트에서는 강화학습을 설명하기 앞서, Markov Decision Process가 무엇인지 먼저 간단하게 살펴보겠다.
1. Markov Process
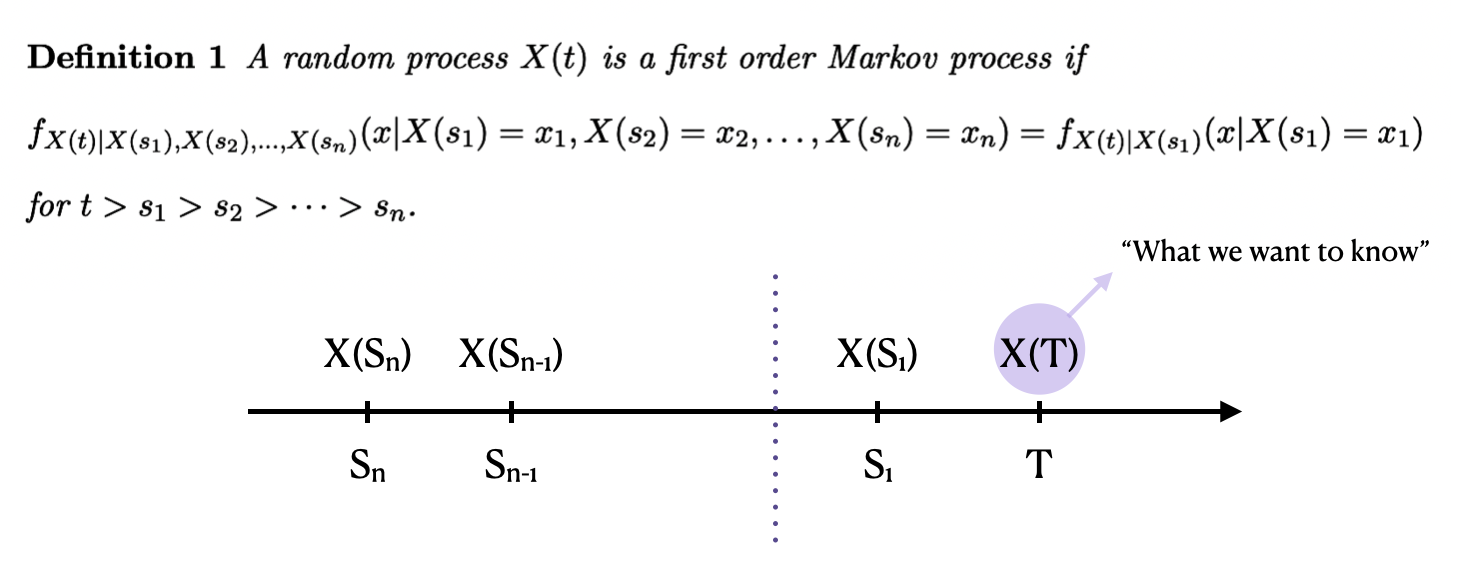
Random process (어떤 실험결과를 하나의 함수에 대응시키는 것으로, 하나의 값에 매핑하는 random variable과 유사하다고 보면 된다)인 X(t)가 다음과 같은 조건을 만족할 때, 우리는 마르코브 프로세스이다 라고 말한다. Sn ...T까지의 discrete한 시간 흐름이 있다고 가정하자. S1까지 X(Sn) .. X(S1)의 시그널이 발생했을 때, (우리가 이미 알고있는 관측값) 우리가 이들로 conditioning 한 X(T)의 probability는 사실 Sn ... S2와는 상관없이 오직 현재 상태인 X(S1)로 conditioning한 probability density와 같다. 이는 다시 말하면 미래는 과거와 독립적이며 이를 통해 나중에 설명할 강화학습은 현재 시점에서 미래를 예측하고 그에 따르는 의사결정을 할 수 있게 된다.
2. Markov Chain with Rewards

특히 Markov 과정이 정수값을 지닐 때 우리는 Markov chain이라고 부르며 이는 위 좌측 그림처럼 directed graph로 나타낼 수 있다. S0,...,S3이라고 표기된 노드는 state를 의미하는데 이러한 state간에 이동하는 것이 바로 다음과 같은 수식으로 표현된 transition이다. n-1시간부터 먼 과거까지의 state 정보를 알고 있을때, 시간 n에서의 state X가 j일 조건부확률을 구한다고 하면, markov property에 의해 너무 먼 과거들은 영향을 미치지 못할 것이고 따라서 내가 원하는 시간의 바로 직전 시간인 n-1로 conditioning한 확률값으로 될 것이다. 이는 Pij(n)이라 표현하며 시간 n에서 state i에서 j로 갈 확률을 의미한다. 예를들어 P0,3은 state0에서 state3으로 이동할 확률을 의미한다. 이러한 transition probability를 matrix형태로 표기한 것을 state transition probability matrix라 부르며 통상적으로 S라고 표기한다.
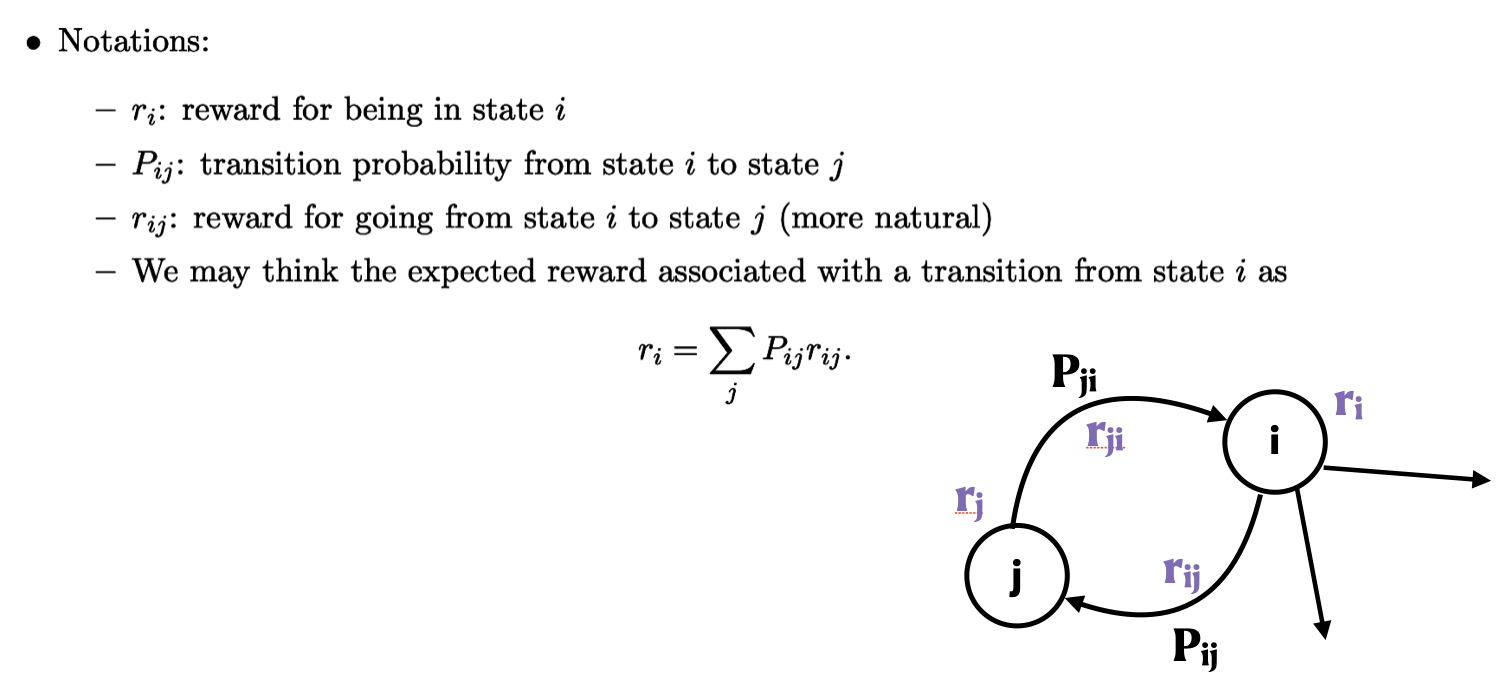
기본적인 Markov Process에서는 각 state 별로의 transition 확률이 주어질 뿐 현재 state에서 다음 state로 가는 것이 얼마나 가치 있는 일인지는 알 수 없다. 따라서 이를 정량화하기 위해 도입한 개념이 바로 reward이다. 이때 특정 state에 있을 경우의 reward는 그 state에서 나가는 모든 reward와 transition의 합으로 얻어질 수 있다.
3. Markov Decision Process
sunny rainy sunny 0.8 0.2 rainy 0.6 0.4 다음과 같이 오늘 날이 좋을 때 내일도 좋을 확률이 0.8, 내일은 비가 올 확률이 0.2/ 오늘 비가 오는데 내일은 맑을 확률이 0.6, 내일도 비 올 확률이 0.4인 markov chain이 있다고 가정하자. 이럴 경우 state space는 {sunny, rainy}가 될 것이며 transition은 각각의 확률값으로 표시가 될 것이다. 여기까지는 여태까지 이야기한 마르코브 체인과 동일하다. 하지만 오늘 날이 맑았을 때 만약 어떠한 신이 존재하고, 내가 간절하게 "제발 내일도 맑게 해주세요"라고 기도하는 action을 취하면 어떻게 될까?
Pray for Sun Sunny Rainy Sunny o 0.9 0.1 Rainy x 0.6 0.4 그렇게 된다면 action이 process에 영향을 주게 되어 {Pray for Sun}이라는 새로운 action space가 생기게 된다. 또한 그러한 action space로부터 영향을 받아 transition probability가 바뀌게 된다. 다시 말하자면 이전의 Markov Process에서는 transition에 의해 state가 다른 state로 이동한다고 한다면, MDP에서는 action에 의해 state가 이동하게 된다.

따라서 MDP는 다음과 같은 4개의 요소로 표현할 수 있으며 이는 각각 state, action, transition, reward를 의미한다. 이때 transition은 state에 action을 추가해 state으로 가며 (이러한 이유로 function of action of state라고 불리기도 한다.) state에 action을 취해 또다른 reward가 발생한다는 특징이 있다.

그렇다면 우리는 MDP 문제를 어떻게 풀 수 있을까? MDP의 solution은 위 주황색 박스들로 구할 수 있다. 먼저 𝝅(s)는 state에 대한 action의 distribution을 나타내는 것으로 policy라고 부른다. 이는 현재 state에서 action을 취해 다른 state s'로 갈 확률과 그럴 때 모일 value들의 합을 가장 크게 하는 action을 선택함으로 얻어진다. 그렇다면 그러한 policy를 따를 때 얻어지는 value인 V(s)는 어떻게 구하는 것일까? value는 현재 state에서 얻는 reward와 앞으로 얻을 reward의 합으로 구한다. 왜 현재만의 reward 뿐만 아니라 부가적인 요소도 더하는지에 대해 말하자면, 좋은 정책이란, 현재의 보상을 최고로 취할 수 있는 action이 아닌, 현재부터 나의 target goal까지의 reward들의 합을 최대화하는 action을 행하는 것이기 때문이다.
이렇게 간단하게 Markov Decision Process에 대해 설명을 해보았다. 다음 시간에는 이러한 MDP의 성질을 지니는 Reinforcement Learning이 무엇인지에 대해 이야기하고자 한다.
'Deep Reinforcement Learning' 카테고리의 다른 글
Planning by Dynamic Programming (by Silver) (0) 2022.03.29 1. Introduction to Reinforcement Learning (0) 2022.02.28 Reinforcement learning란? (0) 2021.12.23