-
1. Introduction to Reinforcement LearningDeep Reinforcement Learning 2022. 2. 28. 14:17
오늘 포스트에서는 강화학습에 대한 특성과 용어정리를 하고 넘어가겠다.
1. Reinforcement Learning(강화학습)의 다른 ML paradigm과 다른 특징
- Supervisor없이, 오직 reward signal만이 있다. → 강화학습은 알아서 reward받는 것을 maximize하는, optimal에 도달하는 방법론이다!
- Feedback(reward)은 즉각적으로 오지 않을 수 있다. (delay될 수 있다.)
- 각각의 action의 순서가 유의미하다.
- Agent들의 action은 들어오는 subsequent한 data에 영향을 미친다.
2. 용어정리
● Rewards
Reward는 step t에서 agent가 얼마나 잘 하고 있는지에 대한 feedback signal로, 벡터가 아닌 스칼라 값이다. Agent의 일은 바로 이 축적된 reward들을 최대화하는 것이다.
Reinforcement learning은 reward hypothesis에 기반한 것이라고 할 수 있다.

강화학습의 goal : 모든 미래 reward 값들의 합을 최대화하는 action을 고른다. 이때, 앞서 이야기했던 것처럼 action에 대한 결과가 나중에 오거나 reward가 delay될 수 있다.
● Agent and Environment

Action(우리가 학습하는 것)을 하면 environment가 두가지의 신호를 준다 : (1) reward (2) observation.
● History and State
History는 observation, action, reward의 sequence값이다. (Observation On을 받고, Reward Rn을 받아서 action An을 했다!)
이때 Ht는 t까지 있었던 모든 것들의 기록을 의미한다.

agent는 히스토리를 보고 action을 취하며, environment는 히스토리를 보고 나서 observation 혹은 reward를 부여하기 때문에 다음에 무엇이 일어날지는 history에 의해 일어난다.
History보다 더 중요한 개념은 바로 state이다.
State란, 다음에 무엇이 일어날지를 결정하는 information을 의미한다. State와 History는 약간 다른데, state는 히스토리 안에 있는 정보를 가공해서 만든다. 다시말해, state는 history의 함수이다.

State를 좀 더 자세히 설명하기 위해 environment state와 agent state로 나누어서 설명하도록 하겠다.
(1) Environment State

Environment state는 다음 값을 계산하기 위해 환경이 내적으로 갖고 있는 표현형으로 보통 agent한테는 보이지 않는다. 쉽게 말하자면 Environment는 observation과 reward를 계산하는 역할을 하며, Environment state란 그 둘(observation이랑 reward)를 계산하는데 쓴 모든 정보들을 말한다.
(2) Agent State

Agent State란 다음 action을 하기 위해 필요한 정보들을 의미한다.
An RL agent may include one or more of these components:
Policy: agent’s behaviour function
Value function: how good is each state and/or action
Model: agent’s representation of the environment● Policy
Policy는 state으로부터 action으로 매핑해주는 map이다. policy는 크게 두 종류로 나뉠 수 있는데, deterministic policy는 액션 하나를 뱉어주는 반면 stochastic policy는 여러 가능한 액션들의 확률을 뱉어줌으로 agent는 확률에 따라 하나의 액션을 선택한다.

● Value function
Value function이란 상황이 얼마나 좋은지를 나타낸다. 더 정확하게 말하자면 value function은 future reward의 prediction으로, state의 좋고 나쁨을 평가한다. Policy, 즉 어떻게 게임할건지에 따라 value(즉 future reward)가 많이 달라진다.
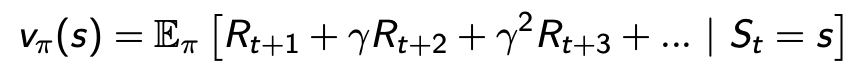
위 수식을 좀 더 자세히 살펴보자. 좌측의 v(s)는 state S로부터 어떤 policy π를 따라갔을 때, 게임이 끝날때까지 얻게되는 총 리워드의 기대값을 의미한다. (policy가 없다면 value function은 정의되지 않는다!!)이제 우측을 살표보겠다. 수식에 보이는 Υ는 discount factor이며 미래 리워드는 불확실하므로 조금씩 줄여서 예측한다. (불확실한 미래값에는 적절한 weighting을 주어 전체 value 계산에 영향이 덜 가게끔 한다.)
Stochastic policy의 경우 같은 state에서도 어떤 확률로 무엇을 선택하느냐에 따라 reward가 달라지기 때문에 전체 가능한 reward들의 기대값을 취해준다. 그렇다면 deterministic policy에서는 이 수식이 매우 간단해질까? (액션하나를 뱉어주니 E(기대값)도 하나일테니 말이다!) 정답은 '아니다'이다. value function에서 확률적인 요소가 policy를 제외하고도 environment 자체에 확률적인 요소가 있을 수 있기 때문이다.
'Deep Reinforcement Learning' 카테고리의 다른 글
Planning by Dynamic Programming (by Silver) (0) 2022.03.29 Reinforcement learning란? (0) 2021.12.23 Markov Decision Process (0) 2021.11.17